Semantic Context based Active Robot Exploration
My Bachelors' Thesis Project at IIT Guwahati was guided by Prof. S. K. Dwivedy of the Mechanical Engineering department, and Prof. Prithwijit Guha of the Electrical and Electronics Engineering department.
My work was on Semantic Context based Active Robot Exploration (SAREx). SAREx is intended to infuse a robot with the knowledge that a human has of the scene, by combining semantic scene understanding techniques with human demonstrations of suitably intelligent decisions in the environment. The understanding thus serves as a context for the robot's future decisions. Broadly, there are two areas of concern:
We have submitted a paper on this concept to AAMAS 2016, currently under review:
My work was on Semantic Context based Active Robot Exploration (SAREx). SAREx is intended to infuse a robot with the knowledge that a human has of the scene, by combining semantic scene understanding techniques with human demonstrations of suitably intelligent decisions in the environment. The understanding thus serves as a context for the robot's future decisions. Broadly, there are two areas of concern:
- Semantic Scene Understanding
- Learning from Demonstration via Inverse Reinforcement Learning
We have submitted a paper on this concept to AAMAS 2016, currently under review:
- Tanmay Shankar, Santosh K. Dwivedy, and Prithwijit Guha, "Semantic Context based Active Robot Exploration.", International Conference on Autonomous Agents and Multiagent Systems - AAMAS 2016
Semantic Understanding based Context
I worked on a framework to provide the robot with a semantic understanding of its environment. This understanding serves as a context for its decisions, functioning in much the same way as humans do. To construct such a contextual understanding, I used two types of semantic relationships:
- Object - Concept relationships
- Spatial Object relationships

The robot used for context based exploration. Notice the simple differential drive, and the Kinect mounted on top.
Object Concept Relationships
The robot first identifies a set of objects present in the scene, and estimates a set of activities, or concepts, potentially occurring in the scene. By deriving a set of additional objects required to execute these concepts, I provided the robot with a semantic context of the scene.
The robot is aware of some subset of objects present in the scene, we would like to estimate what concepts are potentially occurring in the scene. The robot may then identify additional objects required to execute these concepts, and subsequently search for the remaining undetected objects. To effectively utilize such object-concept relationships, I built a framework for the robot to first learn these relationships, and then leverage these relationships.
The robot is aware of some subset of objects present in the scene, we would like to estimate what concepts are potentially occurring in the scene. The robot may then identify additional objects required to execute these concepts, and subsequently search for the remaining undetected objects. To effectively utilize such object-concept relationships, I built a framework for the robot to first learn these relationships, and then leverage these relationships.
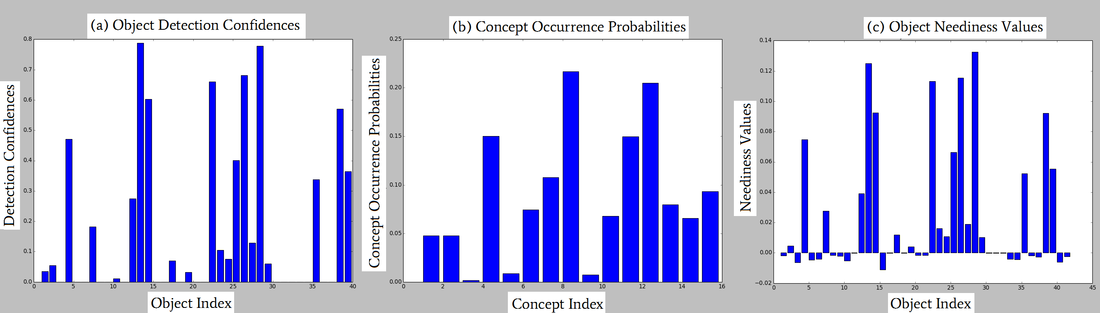
Depiction of querying object-concept relationships. The system sequentially (a) finds object detection
confidences for all objects, (b) estimates potential concept occurrence probabilities, and (c) computes additional
object neediness values.
Spatial Object Relationships
Once the robot determines which concepts and additional objects are occurring in the scene, it is necessary for it to estimate where these objects are present in the scene. By learning quantitative spatial relationships between pairs of objects, I built a model that generates a value function for each objects, defining the likelihood of occurrence of a particular object at a specific location in the scene.
I exploited spatial relationships or relative spatial positions between pairs of co-occurring objects in the scene for this purpose. Of interest were quantitative measures involving relative distances between object centroids, making use of these relative distances as a robust invariant feature. The spatial relationships between two objects i and j are qualified by a mean radius r_ij , and standard deviation σ_ij . The learning and querying phases were taken up individually.
I exploited spatial relationships or relative spatial positions between pairs of co-occurring objects in the scene for this purpose. Of interest were quantitative measures involving relative distances between object centroids, making use of these relative distances as a robust invariant feature. The spatial relationships between two objects i and j are qualified by a mean radius r_ij , and standard deviation σ_ij . The learning and querying phases were taken up individually.

Sample point-cloud of scene, created from a mapping exercise. The chair, desk, and drawers present suggest the scene is of a workplace.
Learning from Demonstration via Inverse Reinforcement Learning
I developed an alternate approach to Learning from Demonstrations using Inverse Reinforcement Learning for estimating reward functions, to help the robot learn how to autonomously explore the environment to locate the needed objects based on expert demonstrations.
Learning from Demonstrations gives the robot the capacity to generalize expert demonstrations of navigation in an environment. By tying these demonstrations to maximize the increase in expected reward at every time step,
By tying these demonstrations to an Inverse Reinforcement Learning framework, I estimated the reward function, expressed as a linear combination of value functions corresponding to the spatial likelihood of occurrence of objects and costmaps for obstacles respectively.
Learning from Demonstrations gives the robot the capacity to generalize expert demonstrations of navigation in an environment. By tying these demonstrations to maximize the increase in expected reward at every time step,
By tying these demonstrations to an Inverse Reinforcement Learning framework, I estimated the reward function, expressed as a linear combination of value functions corresponding to the spatial likelihood of occurrence of objects and costmaps for obstacles respectively.
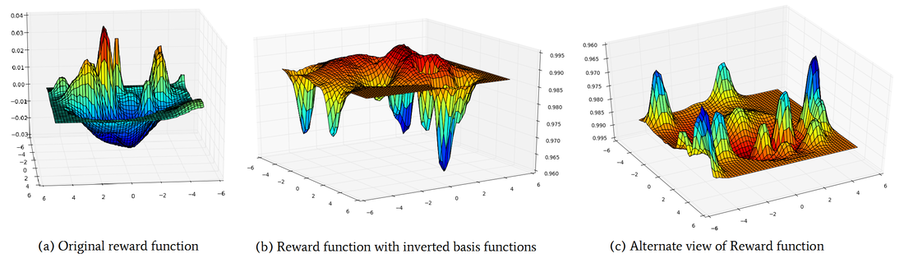
Plot of the computed reward functions. The flipped basis rewards are depicted in (b) and (c). The horizontal axes represent the environment space coordinates, and the vertical axis represents the reward value. Constituent value functions and cost-maps dominate the reward in various regions, thus leading to a overall reward that suitably guides the robot through the environment.
The approach I developed was based on the proposition that an expert user maximizes the increase in expected reward at every step, in contrast with the max-margin approaches used in literature. This solution is hence much faster - eliminating the need for an iterative solving of an MDP.
Once the reward function is estimated, the robot then uses this reward function to autonomously explore the environment and identify additional objects required to execute the estimated set of activities.
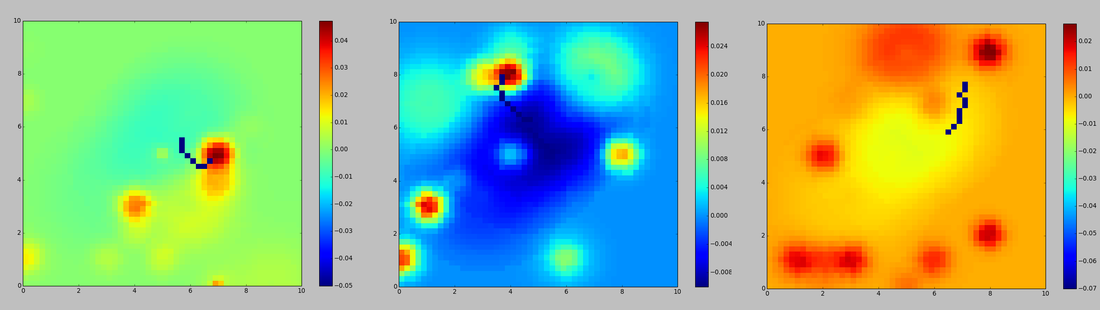
Plot of exploration of the reward functions. The robot is initialized at a random position. The dark blue
segments represent the outward paths taken towards the optima of the reward function. The exploration occurs in accordance with the exploration policy, while the paths depicted are terminated for clarity.
